Chapter1.信使(The Messenger)
乔治·伽莫夫在将注意力转向破解生命密码之前,已经解决了许多重大的科学问题。1904 年出生于黑海港口城市敖德萨的伽莫夫,六岁时从自家公寓楼顶看到哈雷彗星后,便开始思考宇宙的奥秘。四十年后,他成为"大爆炸"宇宙起源理论的世界领军倡导者。伽莫夫的同僚们视他为天才——"又一个海森堡",尼尔斯·玻尔如此评价,将他与这位诺贝尔奖得主、量子力学先驱相提并论;但也是个怪人,"一个在原子、基因到太空旅行之间跳跃的巨人小恶魔",吉姆·沃森这样形容。
伽莫夫因其 6 英尺 6 英寸(约 1.98 米)的身高和顽皮的幽默感而与众不同,即便在最严肃的学术场合也不例外。当他与学生拉尔夫·阿尔弗共同发表关于化学元素宇宙起源的理论时,伽莫夫特意加上了同事汉斯·贝特的名字,仅仅是为了凑成"阿尔弗-贝特-伽莫夫"这样符合希腊字母顺序的作者列表。
1933 年从苏联叛逃后,伽莫夫于次年抵达美国。作为华盛顿特区乔治华盛顿大学长达 20 年的物理学教授,他最终来到了我所在的科罗拉多大学博尔德分校——校园里最高的建筑"伽莫夫塔"(物理系所在地)正是为纪念他而命名。尽管伽莫夫在核物理和宇宙学领域崭露头角,但到 20 世纪 50 年代初,他确信最令人振奋的待解科学问题与宇宙起源或亚原子粒子行为毫无关联。事实上,这个问题根本不属于物理学范畴。
1953 年 6 月,伽莫夫在《自然》杂志上读到吉姆·沃森和弗朗西斯·克里克那篇具有里程碑意义的文章,宣布 DNA 结构为双螺旋。这一结构完美解答了一个重大谜团:遗传信息如何被复制并传递给下一代。沿着 DNA 链排列的四种化学单元(即碱基)——腺嘌呤(A)、胸腺嘧啶(T)、鸟嘌呤(G)和胞嘧啶(C)——与双螺旋另一条链上的互补碱基形成配对:A 总是与 T 配对,G 总是与 C 配对。
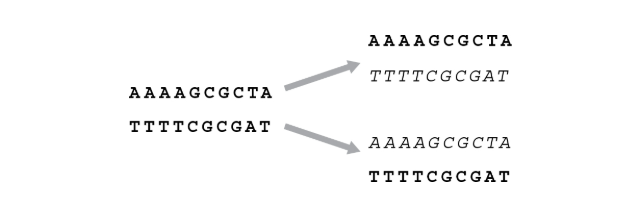
双螺旋结构看起来像一条扭曲的拉链。如果将这条拉链拉开,每一侧都拥有指导构建另一侧所需的全部信息,因为两侧始终完美互补。沃森和克里克推断,这必定是遗传信息复制的方式。
在 1953 年 7 月 8 日的一封信中,伽莫夫祝贺沃森和克里克将生物学带入了“精确科学”的领域。他大胆提议跨学科合作,以解决当时萦绕在每个人心头的下一个重大问题:那些由 A、T、G 和 C 组成的字符串中所编码的信息,究竟是如何被读取并最终决定一只手、一颗心脏、一个肝脏或一个大脑的——又或是格里高利·孟德尔花园中皱皮与光滑的豌豆。这位奥古斯丁修道士最早提出,这些性状以某种基本单位的形式代代相传,如今我们称之为基因。伽莫夫表示,他可以帮助沃森和克里克运用数学和物理学来破解这一遗传密码。
沃森和克里克对一位著名物理学家对他们的工作感兴趣感到受宠若惊,但沃森回忆说,伽莫夫的手写信“充满了异想天开的特质,以至于我们不知道他有多认真”。伽莫夫是非常认真的。在接下来的几个月里,他全身心投入到破解遗传密码的工作中。当时他是美国海军的顾问,因此他不仅寻求化学家和物理学家的帮助,还寻求军事密码学家的协助。然而,事实证明,解开 DNA 的这个秘密最终需要 DNA 自己的“女儿”——核糖核酸,即 RNA。
藏在领带中的迷
从生物学角度来说,“破译遗传密码”意味着理解 DNA 如何编码蛋白质。生命由蛋白质构建,它们是生物圈中每个有机体内主要的驱动者和执行者。在人类体内,一些蛋白质构成肌肉纤维、皮肤和毛发等结构;另一些作为酶,将摄入的食物分解为基本成分并回收利用这些片段来构建新的细胞机器;还有些蛋白质在细胞膜上形成孔道,选择性允许某些盐分或营养物质进入细胞并排出其他物质;其他蛋白质则充当信号分子,接收外界信息并相应激活内部进程;此外还有抗体这类蛋白质,保护我们免受病毒等外来入侵者的侵害。简而言之,蛋白质具有惊人的多样性。
从化学角度讲,蛋白质是由一百甚至上千个氨基酸组成的聚合物长链。这些氨基酸构件共有 20 种类型,名称诸如赖氨酸、缬氨酸和苯丙氨酸。每条蛋白质链上的氨基酸都具有特定的排列顺序(即序列),该序列决定了蛋白质如何折叠成具有特定功能的三维实体——例如在胃中消化食物,或在大脑中传递神经信号。因此,尽管我们常听说需要吃鱼、豆腐或"不可能汉堡"来"获取足够的蛋白质",但实际上并不存在单一的蛋白质,而是成千上万种不同的蛋白质。每一种蛋白质都由其自身的基因编码,而这些基因由 DNA 构成。
自 20 世纪初以来,化学家们对 RNA 和 DNA 进行了分析,发现它们是由相同的生化材料构成的。它们的全名——脱氧核糖核酸和核糖核酸——揭示了它们之间的密切关系。“脱氧”意味着 DNA 的每个重复单元比 RNA 少一个氧原子;这额外的氧原子使得 RNA 在化学上比 DNA 不稳定得多。
数十年来,DNA 和 RNA 被视为无功能的化学物质。与蛋白质相比,它们对科学家的吸引力要小得多,因为蛋白质作为酶和信号分子(如胰岛素)的作用显得格外引人注目。直到 1944 年,洛克菲勒研究所的奥斯瓦尔德·艾弗里及其同事发现 DNA 是导致细菌遗传变化的分子,这一发现与 1953 年沃森和克里克揭示 DNA 双螺旋结构的成果相结合,DNA 才成为生物学的核心。由于科学家早在 1947 年就提出 RNA 是从 DNA 复制而来的理论,他们现在认为 RNA 在生命化学中也必定扮演着重要角色。
尽管 RNA 通常是单链结构,而 DNA 呈双螺旋形态,但两者使用的是同一种语言。与 DNA 一样,RNA 由四个字母的字母表构成。前三个字母——A、G 和 C——与 DNA 相同。第四个字母 U(尿嘧啶)在 RNA 字母表中的位置对应于 DNA 中的 T(胸腺嘧啶)。因此,当 RNA 从 DNA 复制而来时,它携带了相同的信息。
一如既往地热衷于宏大而全面的理论,伽莫夫最初仅凭铅笔、纸张和他的大脑试图解决编码问题。1953 年,也就是双螺旋结构被发现的那一年,他提出了一个理论,认为三个碱基可能编码一个氨基酸。他的推理是基于数学的。如果你用 DNA 或 RNA 字母表中的四个字母,尝试尽可能多地组成两个字母的组合,你只能得到 16 种组合——这不足以指定构成蛋白质的 20 种氨基酸。但如果你尝试将 DNA 或 RNA 字母表中的四个字母排列成尽可能多的三个字母的组合,你会得到 64 个这样的三联体密码子——足以指定 20 种氨基酸,甚至还有剩余。更长的碱基组合也能完成这个任务,但三个就足够了;这是遗传密码最经济的格式。
但是哪三个碱基的组合编码了哪种氨基酸呢?尽管伽莫夫召集了二十世纪一些最伟大的天才,最终 RNA 领带俱乐部的杰出成员们也只是把自己绕进了死胡同。到了 20 世纪 50 年代末,伽莫夫放弃了破解密码的尝试,他确信这个问题“没有解决方案”,无法通过“纯理论的基础”找到答案。
伽莫夫真正需要的是一块生物学上的罗塞塔石碑。这块石碑上不会同时刻有埃及象形文字和希腊文,而是会显示蛋白质的氨基酸序列以及编码它的 RNA 序列。但这样的石碑并不存在;科学家们需要自己设计一个。为此,他们必须确定这个假想中的“信使”是否真实存在——RNA 是否真的是连接我们的基因与生命蛋白质构建模块之间缺失的一环。
你收到我的信息了吗?
20 世纪 50 年代,包括吉姆·沃森和弗朗西斯·克里克在内的许多科学家都热切相信 RNA 可能将信息从细胞核中的 DNA 传递到合成蛋白质的细胞质中。但当科学家试图寻找 RNA 是生命信使的经验证据时,他们最初的结果令人失望。第一个失望是发现细胞质中的大部分 RNA 的 A、G、C 和 U 碱基比例相同,与正在合成的蛋白质无关。这说不通——就像发现贝多芬的第九交响曲与 Lady Gaga 的《Bad Romance》中每种音符的比例完全相同一样。你会预期这些截然不同的音乐作品在升 F 和降 B 等音符的分布上会有相应的差异。同样,你会预期不同蛋白质因其氨基酸组成不同,在指定它们的信使 RNA(mRNA)中 A、G、C 和 U 的比例也会不同。
第二个令人失望的发现是,细胞质中的大多数 RNA 非常稳定——一旦生成,就能存在很长时间。但科学家们已经观察到,细胞中制造的蛋白质可以在几分钟内迅速从一组蛋白质切换到完全不同的另一组。例如,如果改变细菌的食物来源,它们会停止制造用于消化旧食物的酶,并立即开始制造适合新食物的酶。同样,如果细菌被病毒感染(细菌也会受到自身病毒的困扰,这些病毒被称为噬菌体或 phage),它会从制造细菌蛋白质转变为制造噬菌体蛋白质。因此,真正的 mRNA 需要不稳定,以便能够快速改变正在制造的蛋白质。而大多数细胞 RNA 的极度稳定性似乎使其不符合科学家们寻找的信使分子的标准。
在那些坚信必定存在某种尚未被发现的 mRNA 的科学家中,巴黎巴斯德研究所的弗朗索瓦·雅各布和雅克·莫诺便是其中两位。他们曾对细菌中基因如何开启和关闭做出过开创性发现,此时正将注意力转向 RNA。1960 年,雅各布造访英国剑桥时,在国王学院布伦纳的房间里与好友弗朗西斯·克里克、悉尼·布伦纳等人会面。雅各布描述了他关于细菌基因调控的最新实验,谈话很快转向了对信使 RNA 作为基因与蛋白质之间桥梁作用的激动人心的推测。
突然,几乎是同时,克里克和布伦纳跳了起来。他们想起了田纳西州橡树岭国家实验室的两位科学家肯·沃尔金和拉里·阿斯特拉汉最近的实验。在研究被一种名为 T2 的噬菌体感染的大肠杆菌时,沃尔金和阿斯特拉汉观察到新 RNA 的快速形成,这些 RNA 比细胞中的稳定 RNA(现在已知是嵌入核糖体中的 RNA,核糖体是细胞的蛋白质工厂)要小。由于一系列复杂的原因,沃尔金和阿斯特拉汉将他们的数据解释为 RNA 正在转变为 DNA。但如果他们实际上瞥见了难以捉摸的 mRNA 呢?
这是一个令人兴奋的可能性,但要证实 mRNA 假说,还需要更直接的测试。几周后,西德尼·布伦纳和弗朗索瓦·雅各布计划拜访加州理工学院的遗传学家马特·梅塞尔森——他们决定三人一起进行关键实验。梅塞尔森和他的同事弗兰克·斯塔尔最近使用了一种新技术,涉及一台超高速离心机,来验证沃森和克里克的猜想,即 DNA 复制时双螺旋的两条链会分开。他们的结果支持了这一理论,发现每个子代双螺旋都保留了来自亲本的一条“旧”链,并与一条新合成的链配对。
现在,布伦纳、雅各布和梅塞尔森将使用同样的超速离心机,试图在核糖体 RNA 的“干草堆”中寻找 mRNA 这根“针”。他们的计划是用噬菌体感染大肠杆菌,这将导致细菌改变其正在生产的蛋白质类型。在科学家们添加噬菌体的同时,他们还会加入一种放射性标记的尿嘧啶(用碳-14 标记),这种尿嘧啶只会被整合到新合成的噬菌体 mRNA 中,而不会进入预先存在的细菌 RNA 中。如果 mRNA 假说成立,那么新的噬菌体 mRNA 就会在这一刻出现——从而让他们捕捉到 DNA 与蛋白质之间缺失的这一环。
果然,布伦纳、雅各布和梅塞尔森在超速离心机中观察到了放射性标记的噬菌体 mRNA,它明显比核糖体的 RNA 要小。正如预测的那样,这种 RNA 寿命短暂,它与受感染细菌中预先存在的核糖体结合,生产出噬菌体进行其“肮脏工作”所需的新型蛋白质。他们终于捕捉到了 mRNA,尽管它曾经如此难以捉摸。
思考这一生物过程的一种方式,可以想象一台留声机。核糖体是你的转盘,mRNA 是黑胶唱片,而蛋白质则是当你放下唱针时听到的音乐。你可能会根据心情更换唱片,但其余的设备保持不变。正如留声机可以播放任何黑胶唱片一样,核糖体也能处理任何到来的 mRNA。mRNA 决定了产生的特定蛋白质——无论是噬菌体蛋白、大肠杆菌蛋白还是其他什么——就像唱片决定了你听到的音乐一样。
科学家们之所以难以检测到 mRNA,是因为在大肠杆菌中,只有约 5%的 RNA 是信使 RNA(mRNA),其余 95%主要是核糖体 RNA(rRNA)。此外,大肠杆菌拥有 4000 种不同的基因,每种基因产生的 mRNA 大小和序列各不相同,因此任何一种特定的 mRNA 都远低于 5%的总量。最后,大多数大肠杆菌 mRNA 的寿命仅有几分钟,这使得它们难以捕捉。相比之下,核糖体 RNA 不仅遍布细胞质,而且寿命极长——这就不难理解为什么先驱科学家们花了这么长时间才透过重重核糖体 RNA 的干扰发现 mRNA。
一段语言的插曲
想象一下唱片机或许能帮助我们解释核糖体和 mRNA 如何协作制造蛋白质。但要理解 RNA 如何编码蛋白质,我们就得关掉音乐,翻开书本。
大多数书籍的页面都充满了书面语言——字母、单词、句子。而在以 DNA 语言书写的生命之书中,我们不像英语那样有 26 个字母,也不像希伯来语那样有 22 个字母,而是只有四个字母:A、G、C 和 T。这四个字母的排列方式——它们的序列——将决定每个单词和每个句子的含义。
那么,我们需要多少本书才能涵盖生命的意义——或者说,记录一个特定生物体内所有的 DNA 呢?答案自然取决于基因组的大小,基因组即生物体内 DNA 的总和。人类基因组分布在 23 条染色体上,约有 30 亿个碱基对,或者说“字母”。
假设使用一种典型字体大小,每页大约能容纳 3000 个字符,那么记录人类基因组将需要 100 万页纸。考虑到一本大部头书籍可能有 500 页,基因组序列将需要大约 2000 本书——这远超家庭图书馆的容量,但仅占本地公共图书馆藏书的一小部分。每条人类染色体由一条线性 DNA 分子构成,大约需要 90 本书来承载。而像大肠杆菌这样的细菌基因组则小得多;其整个基因组存在于一个环状染色体中。包含 450 万个碱基对的它,轻松三本图书馆藏书即可容纳。
正如我们所知,制造蛋白质需要信使 RNA 将 DNA 中编码的信息传递到核糖体。天然存在的 RNA 并非 DNA 这本巨著中整页的复制品,而是具有特定的起始和终止点,这些点不太可能与书页的分界重合。因此,与其说是实体书页的影印件,不如将 mRNA 想象成从电子书中通过几次点击复制到另一个电子文档中的一段文字。我们移动光标高亮显示页面的特定部分,然后将其粘贴到文字处理器的新页面中。(借助便捷的查找替换功能,我们可以同时将 DNA 中的所有 T 变为 RNA 中的 U,这模拟了自然界中发生的化学过程。)
这种复制粘贴的过程——即 DNA 被转录成 mRNA——在我们的体内持续不断地进行着,每当需要合成新的蛋白质时就会发生。被复制成 mRNA 的 DNA 区域会根据特定时间和地点的需求而有所不同。成长中的儿童与完全发育的成人相比,基因组中被复制的部分不同;心脏中被复制的部分也与大脑、肝脏和皮肤中被复制的部分不同。换句话说,这种复制过程受到高度调控。
完成复制粘贴后,我们可以检查 mRNA 的序列。它是由 A、G、C 和 U 组成的阵列,例如
GUAGGGCAUGCCUUCGAAAAUAUUUUGUUAGCGCCUCCUUGGAGUAGAA
假设我们知道如何解码这条 mRNA 上三个碱基为一组的密码子。这是我们的解码词典。我没有用氨基酸,而是选择了每个三联密码子对应的三个字母的英文单词作为其含义:
AUG = The
CCU = big
UCG and UCC = cat
AAA and AGA = ate
AUA = one
UUU = fat
UGU and UAU = rat
CGC = but
CUC = two
CUU = and
GGA = six
GUA and GUU = for
GAA and GAG = you
AAU = now
AUU = see
UUG = fox
UUA and UAA = run
GCG and GCC = out
UGG = fun
AGU and AGC = sun
我的词典词汇量极其有限——只有 20 个单词,类似于 20 种天然氨基酸。其中一些单词由单一密码子编码:比如“fun”由 UGG 编码。其他单词(如“run”、“out”、“sun”等)则由多个密码子编码,这与遗传密码如出一辙。你可能会问,为何自然界会演化出使用如此多密码子(总计 64 个)来编码仅 20 个单词(或氨基酸)的系统?难道没有更优雅的编码结构方式吗?
这种表面上的不优雅正是让伽莫夫等物理学家在生物学领域栽跟头的原因之一。在物理学中,事件大多是可预测的。如果你掌握了麦克斯韦方程组,就能解决经典物理问题。但生物学唯一的法则就是:管用就行。一旦一个系统——无论看起来多么复杂——开始有效运作,就会被进化锁定,变得极难改变。即便优秀工程师能设计出更直接或更高效的系统,这一事实也无关紧要。
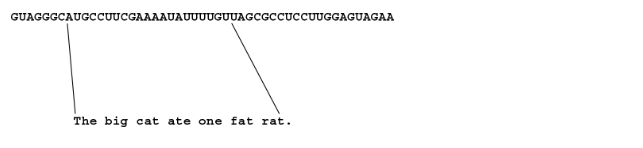
既然我们已经知道如何将密码子串翻译成有意义的单词,现在需要明确信息的起始与终止位置。我们是否应该从左端开始,将 GUA 读作"为了",然后继续向右读取?虽然这看似合理,但自然界另有解决方案。它使用三联体 AUG 来标记句子的起点。我们在此的等效规则是:句子必须以"The"开头,而"The"由 AUG 编码。接下来只需从左端扫描,找到第一个 AUG 并手持字典从该处开始阅读即可。
GUAGGGC AUG CCU UCG AAA AUA UUU UGU UAG CGC CUC CUU GGA GUA GAA
The big cat ate one fat rat
一切顺利,直到我们遇到 UAG 密码子,却发现词典里没有它的条目。哦,对了,我们还需要一个三联体密码子来标记句子的结束——一个句号。‡ 比如说
UAG = end of sentence = period
我们的解码现已完成:
GUAGGGC AUG CCU UCG AAA AUA UUU UGU UAG CGC CUC CUU GGA GUA GAA
The big cat ate one fat rat.
既然我们已经确定了起始密码子 AUG 和终止密码子 UAG,那么用空格分隔密码子就显得多余了。即使 mRNA 序列是以连续字母串的形式给出,只要知道每次读取三个字母,我们依然能获取相同的信息:
即便是伽莫夫假设的密码子三联体性质,在 20 世纪 50 年代也仅是一个合理的猜测。直到 1961 年,弗朗西斯·克里克及其同事通过一系列巧妙的实验,利用吖啶染料对噬菌体基因进行诱变,最终证实了三联体的存在。吖啶染料是类似于 DNA 碱基的扁平分子,它们能嵌入 DNA 双螺旋中,在 DNA 复制时被误认为碱基——从而导致子代 DNA 中插入错误的碱基。想象一下书架上紧密排列的一排书:若强行塞入一本新书,后续所有书籍都必须挪动一个位置来腾出空间;若插入两本,其他书则需移动两本书的宽度。
我们的语言类比可以展示这类插入如何影响信息传递,以及多重插入如何支持三联体密码的构想。以假设的信息为例,我已用斜体标出起始和终止密码子:
GUAGGGC AUG CCU UCG AAA AUA UUU UGU UAG CGC CUC CUU GGA GUA GAA
The big cat ate one fat rat.
当吖啶染料随机插入一个 U(如下划线所示)时,会发生以下情况:
GUAGGGC AUG CCU UCG __U__AA AAU AUU UUG UUA GCG CCU CCU UGG AGU AGA
The big cat run now see fox run out big big fun sun ate
我们的句子起初是正确的,但插入的 U 碱基改变了阅读框架。我们称之为“移码突变”,这种现象在人类基因组中相当常见,并可能导致囊性纤维化、克罗恩病和泰-萨克斯病等不良后果。移码之所以危害巨大,是因为它使得后续所有密码子都变成无义序列。此外,原本标示句子终止的 UAG 密码子现在也偏离了框架,导致这段无义序列无限延伸。若这是编码蛋白质的 mRNA,产生的蛋白质将毫无功能。
现在让我们观察当向序列中添加两个吖啶分子导致两个碱基插入时会发生什么。这与单碱基插入同样具有破坏性:
GUAGGGC AUG CCU UCG __UU__A AAA UAU UUU GUU AGC GCC UCC UUG GAG UAG
The big cat run ate rat fat for sun out cat fox you.
这种情况下,移码虽然在右端生成了 UAG 终止密码子,但产生的句子仍然是无义序列。若这是 mRNA,最终产生的突变蛋白质同样毫无用处。
最后,我们来研究三个碱基插入的后果:
GUAGGGC AUG CCU UCG UUU AAA AUA UUU UGU UAG CGC CUC CUU GGA GUA
The big cat fat ate one fat rat.
如果密码是一个三联体密码,如图所示,一个异常的单词——“fat”——会被插入到句子中,但其他所有单词都是正确的。这句话大体上还是可以理解的。
这正是克里克及其同事所报告的,证实了伽莫夫最初的假设。一个碱基的插入是致命的。两个碱基的插入同样致命。但三个碱基的插入则基本能保持功能!因此,密码子必须由三个碱基组成一组。
破解密码
伽莫夫和他的 RNA 领带俱乐部已经推断出遗传密码是由三个字母书写的,而 RNA 很可能是 DNA 与蛋白质之间的桥梁。布伦纳、雅各布及其同事证实了后者——明确识别出了信使 RNA,它将我们 DNA 中的信息传递到细胞的蛋白质制造机器——核糖体中。但我们仍然无法解读这些信息。随着 1960 年代的到来,遗传密码依然无法破译——直到一位名叫马歇尔·尼伦伯格的年轻科学家出现。
1959 年,尼伦伯格在马里兰州贝塞斯达的国家关节炎与代谢疾病研究所获得了一个独立研究职位。在转向生物化学并取得博士学位之前,他曾在佛罗里达大学攻读硕士学位,研究石蛾——一类幼虫水生、成虫似蛾的昆虫。(或许尼伦伯格不愿承认自己科研生涯始于研究昆虫,因为他在最终的诺贝尔奖演讲中略去了这段经历。)试图破解遗传密码是尼伦伯格的一次雄心之举。他与该领域的领军人物几乎毫无交集,也从未获赠过象征学术地位的羊毛 RNA 领带。然而,不同于伽莫夫的纸笔推演方法,尼伦伯格决定运用生物化学手段攻克编码难题。这需要通过试管实验重建蛋白质合成过程——即将 mRNA 转化为蛋白质的机制。
尼伦伯格基于波士顿马萨诸塞总医院的生物化学家伊丽莎白·凯勒和保罗·扎梅克尼克的突破性工作,他们开发了一种利用从大鼠肝脏中提取的成分在细胞外合成蛋白质的方法。扎梅克尼克等人随后证明,大肠杆菌的提取物也可以实现同样的效果。这成为了尼伦伯格的实验系统。简而言之,该方法包括破碎大肠杆菌以获取粗制的核糖体制备物,然后添加不同的 RNA 序列作为蛋白质合成的模板。
在多次错误的引导后,尼伦伯格和他的博士后研究员海因里希·马特埃偶然发现,一个完全由 U 碱基组成的简单 RNA 分子,称为聚尿苷酸(poly(U)),能够指导合成仅由苯丙氨酸组成的单一蛋白质。聚尿苷酸的妙处在于,无论从何处开始读取,都只能得到一种三联体密码子 UUU——并且它仅被翻译为苯丙氨酸。因此,遗传密码之谜的第一块拼图被破解:UUU 编码苯丙氨酸。
现在,前进的道路变得清晰起来:将不同的 RNA 序列输入核糖体,看看会产生什么蛋白质。 利用这种方法,发现多聚(C)和多聚(A)分别编码多脯氨酸和多赖氨酸。 于是,密码子分配表越来越多:3 个已经完成,还有 61 个。 当然,前三个很容易,因为三重密码子中的每个字母都是相同的。 更复杂的密码子需要不同的方法。
戈宾德·科拉纳登场了。他出生于当时属于印度、现为巴基斯坦境内的赖布尔一个贫困的印度教家庭,曾在英格兰和瑞士接受教育。作为威斯康星大学麦迪逊分校的教授,他因破解遗传密码的研究首次崭露头角。他与团队发明了化学合成 DNA 的方法,逐个拼接核苷酸,并利用新发现的酶将 DNA 复制为 RNA。这一方法的精妙之处在于能精确控制 DNA 的碱基序列,从而决定所复制 RNA 的序列。将这些 RNA 放入试管蛋白质合成系统后,它们作为信使指定对应的氨基酸序列。通过合成所有可能的三碱基排列组合,将其输入试管系统并观察产生的氨基酸链,科拉纳协助完善了遗传密码表——这一成就使他与马歇尔·尼伦伯格共同荣获 1968 年诺贝尔生理学或医学奖。
在新闻中读到这些发现后,加莫夫感到很满意,因为终于有人解决了编码问题,尽管他忍不住对实验方法嗤之以鼻。"这个解决方案看起来远不如我最初设想的简单理论相关性那么优雅,"他说,"但它有一个无可争议的优点,那就是正确。"
小小 RNA 肩负重任
阐明 mRNA 用来指定蛋白质的代码是一项巨大的成就,但这并不是唯一需要回答的大问题。 有了代码是至关重要的,但然后呢? 必须有一个 "读出 "代码的过程。 mRNA 如何将氨基酸放到正确的位置,然后串联起来构建蛋白质?
弗朗西斯-克里克(Francis Crick)于 1955 年提出了这一问题的答案,他的提议堪称生物学理论的一次伟大胜利。 他创造了一类从未见过的分子,理由仅仅是他认为这些分子一定存在,是遗传密码宏大理论中缺失的部分。 他设想了一组 "适配分子",每个分子都有两端。 一端与 20 个氨基酸中的一个相连。 另一端识别并结合到匹配("同源")的 mRNA 三重密码子上。
你可以把这些氨基酸到 mRNA 的适配器想象成连接电子设备和电源插座的适配器。 要给一副耳机充电,你需要合适的适配器来连接合适的插头,而插头可能会因为你是在美国、英国还是德国而有所不同。 耳机如此,氨基酸也是如此。 你有一个插座(三重密码子)和一个适合插在里面的三叉插头(称为反密码子)。 因为密码子和反密码子是互补的,它们通过碱基配对相互连接。 就像一个可以容纳多个设备的电源插座一样,适配器分子排成一排,把 mRNA 密码子和它们的同源氨基酸连接在一起,形成不断生长的链,最终形成蛋白质。 或者至少克里克是这样提出的。
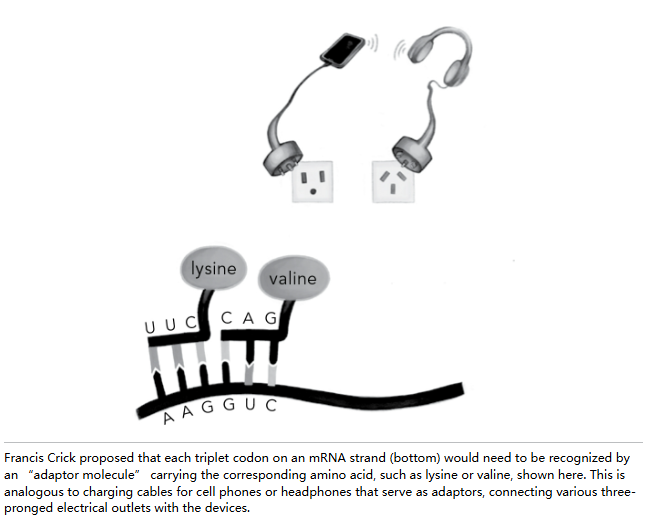
但理论只能带我们走这么远。必须有人走进实验室,看看是否能找到这样的适配分子。这个人就是保罗·扎梅奇尼克,他开发的蛋白质合成方法为尼伦伯格发现第一个密码子提供了关键支持。他首先用碳的放射性同位素标记氨基酸,以便追踪它们的去向——这有点像银行在钱袋里藏一罐会爆炸的颜料,这样如果钱被小偷盗走就能追踪到。当扎梅奇尼克将这些放射性氨基酸加入他的大鼠肝脏系统时,发生了惊人的现象——一些小 RNA 变得具有放射性,表明氨基酸已与 RNA 结合。这种连接以前从未被观察到,但如果存在一种负责将 RNA 密码子适配给氨基酸的 RNA,这正是预期会发生的情况。后来这些小 RNA 被称为转运 RNA(tRNA),因为它们将正确的氨基酸转运到核糖体内不断延长的蛋白质链上。我们将一再看到,转运 RNA 虽小,却威力无穷。
到了 20 世纪 60 年代中期,在一些科学家看来,RNA 的故事似乎已经完结。每条信使 RNA(mRNA)都依据一套已被破译的密码子指令,指导着不同蛋白质的合成。另有两种稳定 RNA 参与蛋白质合成过程:转运 RNA(tRNA)负责将 mRNA 密码子与对应氨基酸连接,而核糖体 RNA(rRNA)——我们稍后将详细探讨——则负责构建蛋白质。
时至今日,许多人仍仅以这种方式看待 RNA,视其为 DNA 的勤杂工,润滑着将生命密码转化为生命实体的细胞机器齿轮。诚然,这一生物学过程对地球上所有生物的生存至关重要。若这真是 RNA 故事的终点,对这个微小分子而言已然是巨大的成就。然而事实证明,信使功能只是 RNA 众多超能力中的第一项。